
Guest Post by: Merziyah Poonawala (Mentee, Session 9, The Product Mentor) [Paired with Mentor, Joni Hoadley]
What do you do when your team is working their socks off and yet they are getting little credit for the work being done, mainly because the team isn’t able to set concrete expectations with the stakeholder? Read on to learn how, through collecting and analyzing their operational data, a team was able to quantify and improve their processes on the path to being able to establish clear release plans for the project.
THE CHALLENGE
A startup development team consisting of a product manager and two offshore engineers was facing major challenges in meeting client deliverable deadlines – repeatedly. Each major release deadline created a high pressure environment with engineers working overtime in the weeks prior in order to meet delivery dates. Deployments to production happened just hours before client demos. The resulting post deployment issues and incomplete setup of new features left the stakeholder conducting a walk through on the concept of the app but not actually able to demo the app to their audience. This obviously reflected as a failure to deliver on part of the engineering team.
This was a team plagued by poor lead time for feature development and unrealistic expectations, set in part by the inability of the team to provide realistic delivery estimates for features.
THE CAUSE
A number of factors were contributing to the team’s inability to plan release milestones and causing general inefficiencies:
No story estimation
The team was not in the practice of estimating stories. With the engineering team being offshore and no group touch points outside of the daily standup, there was little in-depth conversation about implementation or actual scope of work. Without scope discussions, user stories could often run across multiple days making it hard to determine expected delivery.
Lack of sprint planning with the engineers
There was no existing sprint planning or grooming meeting with the engineers. Instead the in-house PM team was using their instinct, based on past story progress, to make decisions on what might be accomplished during each sprint with little buy-in from the engineers. There was no data available to track or predict the actual scope of a sprint. Incomplete stories would be dropped into the following sprint with additional new work. This arbitrary assignment and lack of measurable progress precluded the PM from surfacing possible delivery dates or planning future sprints to create release milestones.
Long standups
Since there was no active grooming or planning session with the engineers, daily standups played the role of requirement review meetings. As engineers picked the next story to work on, the PM would clarify during standup what the requirements and acceptance criteria were for those stories. The team did not have upfront information about upcoming stories to plan their work accordingly and standups were running 30 min each day for a team with two engineers.
Any agile practitioner may recognize these as poor practices and it is surprising how easily a team can succumb when operating in a high pressure, reactive environment.
We decided to introduce some good agile practices with the goal to measure team progress using the team’s velocity so as to generate realistic delivery dates and set the right expectations. If we have a clear picture of how much estimated work is getting done each sprint, we can use estimations to project out delivery dates for new features. Through a series of experiments we brought about changes to improve our team processes and also learn some of the hidden challenges being faced.
THE EXPERIMENTS
Conduct a retrospective:- Our very first move was to call a team retrospective meeting to learn what were some of the gaps and areas of frustration for the engineers and to share the PM’s concern with the existing team process. Since our goal was to be able to establish scope so that we can start estimating, we started by asking how can we better write our user stories so that the engineers received sufficient detail on the requirements and goals of each story. With an offshore engineering team conversation can be limited and communication structures more formal making detailed requirements all the more important. We identified some existing gaps such as having to request missing wireframes and other resources after work started on a story, the need for better functional requirements, and leaving technical details to the engineers. The team also agreed to initiate a weekly meeting to review and clarify requirements and to estimate the user stories.
The retrospective meeting was instantiated on a bi-weekly basis in order to check-in and monitor team health.
Weekly planning with the engineers:- When conducting a weekly planning session with offshore engineers it is important to make sure the engineers are comfortable following and actively participating in the conversation. A good rule for working with remote teams is to make sure everyone is dialing into the online session, even if some members are co-located. This ensures that the onsite folks do not get carried away in an in-depth conversation without active involvement of the dialed in members.
In order to facilitate the review session we agreed to prepare (groom) the upcoming user stories ahead of the planning meeting with detailed requirements. This allowed the engineers to review the upcoming user stories prior to the meeting. Provided everyone did their homework, the review session moved along smoother and faster as the team is familiar with the user stories to be discussed. The engineers would review the stories, think through any implementation concerns and come to the meeting prepared with questions. Discussing the requirements as a team helped the team share their technical knowledge of the codebase with each other.
A benefit of having the weekly planning session and all sprint stories reviewed in detail was that our standups went down to 10 minutes or less daily – a fact that was celebrated by everyone on the team and improved efficiency.
Identifying the “Done” criteria:- Before we could use story points to calculate velocity we needed to agree on a sprint definition of “done” to identify when a user story was considered complete during a sprint. We agreed “done” would be when the user story had been checked in, code reviewed, QAed and deployed into our staging (test) environment. Our sprint was reconfigured to use “Deployed to Staging” as the final step in a sprint.
Story estimation:- The engineering team was fully onboard with estimating user stories using a complexity based framework. Most engineering teams I have worked with will easily embrace complexity based estimation but resist time based estimation as it is not possible for them to say with certainty how long a story will take and thus it sets them up for failure if they do not meet their estimate.
To ensure story pointing was built from a consensus and not dictated by one engineer most familiar with that part of the code we incorporated group voting using an online voting poker tool to allow team members to send in their vote secretly and then reveal all submitted votes simultaneously. If there was a discrepancy in points, we asked the minority why they pointed as they did. After they provided their explanation the same question was opened to the rest of the team. Often the discrepancy resulted from an engineer having more or less previous knowledge or experience working with the specific piece of code.
Reviewing accuracy of story pointing: Estimates are just that – estimates – however depending on your goals it is worthwhile to check in with the team periodically to see how they feel about the accuracy of their estimation and if we were getting some consistency in the work being done. For this particular project story points were our guiding star to extrapolating release dates. Thus while we wanted to continue with a complexity based estimation process being able to pull rough statistics on how story points related to time-to-delivery was valuable information. It allowed the team to consider adjusting the baseline complexity for different task types. Alternately the PM could also factor this when planning release dates.
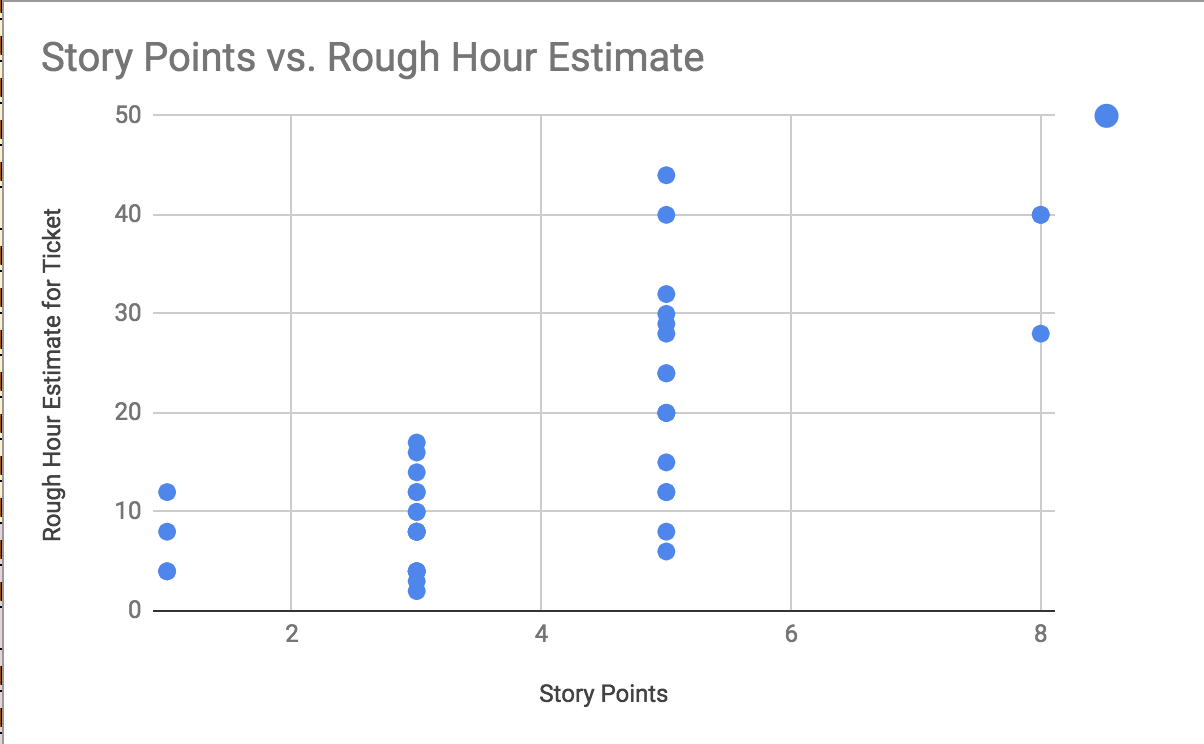
That’s quite a spread, especially for our 5 point stories. Hmm…
I found the velocity we were delivering varied measurably between sprints. To dig deeper I pulled a very rough approximation of the spread of our story points to the number of hours logged and found a large spread between story points and possible completion timeframe. Further analysis revealed a number of factors that contributed to this discrepancy:
- Writing automated tests and refactoring work. Our current codebase had very poor test coverage and as a team we had decided that as we work on an area of code we would go ahead and add additional tests or undertake small refactoring work as needed. This work was not reflected in the story point estimation.
- The nature of the user story: Front-end user stories may have a higher complexity but were quicker to complete and QA than backend user stories or user stories that involved integration with another interface. Integration stories often come with an unknown factor and these stories take longer to complete and to QA. The 5 point stories that exceeded 30 hours were integration stories.
- Re-estimating stories. As a rule we decided not to re-estimate our stories. This helps analyze our velocity based on what was planned. However if a story is dropping across sprints, it is worthwhile to consider re-estimating the remaining work so that the upcoming sprint can be planned according to the story points that will be worked on during that sprint and not inflated by work done in a previous sprint. (This does deflate your previous sprint velocity and thus as you get more stable, you want your sprints planned to minimize work falling across sprints)
- 8 point stories were taking an entire sprint (40 hours). This tells me these should really be broken into smaller chunks.
We let the story estimation process continue for a couple of sprints in order to capture a estimate of what our sprint velocity was averaging.

Fig: A view of our velocity through 12 week period
Capturing team velocity for sprint planning:- As a consistent process was put in place for sprint planning and sprint close we were finally able to review our velocity and get a better grasp on what we can commit to within a sprint. The story points now gave engineers some clarity on the level of work they were comfortable committing to within a sprint and an open discussion on what the team feels they may or may not be able to deliver.
I discussed earlier how our estimates were causing some discrepancies within our weekly velocity. External factors also have a measurable impact on a particular week’s velocity. As seen above having engineers out of office for the week meant our sprint’s deliverable story points needed adjustment on those weeks along with their impact on our release dates. Additionally urgent user reported bugs one week diverted resources to bug fixes instead of the planned sprint. All conditions the PM must build some allowance for when generating release plans.
As we got better at more detailed requirements and refining our estimates we saw our velocity pick up.
FURTHER EXPERIMENTATIONS
Now that the team has a metric to turn to the team can engage in further experiments to refine and tweak the software development process. Some additional improvements/considerations include:
Allocating 20% to non-critical tech debt payoff: With a velocity to work with the team is now able to decide on allocating 80% of the story points to new features and leaving the remaining 20% of time for non-critical bug fixes or issue research. This creates a buffer to our sprint for when stories are blocked or take longer than expected, while scheduling some lower priority, but needed work into the sprint. What needs to be monitored here is that the team is in general able to address these issues allocated to the sprint and that they are not being carried across multiple sprints. If that’s the case, you are overestimating your sprint and need to determine if this work is important enough to bring into your core sprint work or be put aside. Stories carrying over multiple sprints tend to have a demotivating effect on the team.
Estimating refactoring work: When refactoring work becomes significant enough to cause a change in the estimate story point either due to complexity or expected ticket delivery, breaking out the refactoring work as its own story and estimating it can keep the team on track to delivering consistent amount of work across sprints and help in prioritization.
Assigning Stories during sprint planning: As a team we decided on the set of stories to complete during the sprint, but these stories were kept in a prioritized bucket for the engineers to pick from once they finished their current work. One experiment we started was to assign 80% of the sprint stories among the engineers during the planning meeting. I found for some engineers this provides a more clear picture of what they will be working on for the sprint and increases clarity and commitment. It also helped with dependencies and allowed engineers to speak up if they were interested in tackling a specific area of the code.
This was my journey in collecting and using quantifiable data to evaluate our progress and identify the issues and gaps we saw. Some of these issues might be familiar to you, or you may have a different set of challenges. Take the time to evaluate your processes and identify what has been working and what has not. Identifying a goal around process improvements helps you identify what data to track and how to evaluate that data. Regular retrospectives are a good avenue to identify and commit to small experiments, reviewing their outcome and deciding if they should be incorporated into your daily process or if an adjustment is needed. But through continual evaluation and experimentation your can guide your team to increased productivity and happier stakeholders.
Special thanks to Joni Hoadley for her guidance and mentorship through simple but highly effective and actionable suggestions throughout this process.
 Merziyah Poonawala is currently a product manager at Def Method where she guides startups towards their MVP and has stepped in as a consultant to drive the product roadmap and communicate technical challenges up. Previously she worked in the healthcare industry serving a B2B product. When she’s not PMing she enjoys paper crafts, being outdoors and running the Cherry Blossom 10 mile run in Washington, DC
Merziyah Poonawala is currently a product manager at Def Method where she guides startups towards their MVP and has stepped in as a consultant to drive the product roadmap and communicate technical challenges up. Previously she worked in the healthcare industry serving a B2B product. When she’s not PMing she enjoys paper crafts, being outdoors and running the Cherry Blossom 10 mile run in Washington, DC
More About The Product Mentor
![]() The Product Mentor is a program designed to pair Product Management Mentors and Mentees around the World, across all industries, from start-up to enterprise, guided by the fundamental goals…
The Product Mentor is a program designed to pair Product Management Mentors and Mentees around the World, across all industries, from start-up to enterprise, guided by the fundamental goals…
Better Decisions. Better Products. Better Product People.
Each Session of the program runs for 6 months with paired individuals…
- Conducting regular 1-on-1 mentor-mentee chats
- Sharing experiences with the larger Product community
- Participating in live-streamed product management lessons and Q&A
- Mentors and Mentees sharing their product management knowledge with the broader community
Sign up to be a Mentor today & join an elite group of product management leaders!
Check out the Mentors & Enjoy!
Jeremy Horn
The Product Guy
