

Elke keer dat er een (ver)storing is, worden er vragen gesteld over hoe de monitoring van een organisatie is geregeld:
- Zijn de juiste tools aanwezig?
- Zijn er vroege signalen geweest?
- Hoeveel tijd had het IT team nodig om de oorzaak van het probleem te achterhalen en op te lossen?
- Gaven de gebruikte tools het IT team inzicht in het incident toen dit gebeurde?
- Had deze storing voorkomen kunnen worden?
Immers, wanneer een IT-storing optreedt, heeft dit impact op de bedrijfsvoering. De productiviteit van medewerkers wordt minder, klanten kunnen bijvoorbeeld geen transacties uitvoeren en het imago van de organisatie staat op het spel i.v.m. negatieve publiciteit.
Monitoring moet alle kaders van IT bevatten – van hardware tot opslag, van server tot applicaties. Met de focus op het tevreden houden van eindgebruikers, heeft het belang van monitoring op de applicatie niveau, de laatste tijd steeds meer aandacht gekregen. Daar wil ik vandaag meer aandacht aangeven
Applicatie Performance Monitoring verwijst naar de gedetailleerde inzichten die worden verkregen over de prestaties van een applicatie. Het is niet langer voldoende om alleen te weten of een aanvraagproces loopt of niet, of dat de aanvraag reageert op een aanvraag. De markt heeft behoefte aan meer diepgaande inzichten.
In deze blog zullen we ons concentreren op Applicatie Performance Monitoring (APM) – wat is het, waarom is het belangrijk en waarom IT-teams van ondernemingen zich steeds meer hier van bewust worden.
Wat is Applicatie Performance Monitoring (APM)?
Applicatie Performance Monitoring is de strategie en uitvoering van het continu bewaken en volgen van de prestaties van bedrijfsapplicaties en de gebruikerservaring van eindgebruikers. Dit om inzichten te krijgen wanneer deze eindgebruikers toegang krijgen tot de applicaties om trends te begrijpen, afwijkingen te isoleren en bruikbare inzichten te krijgen voor probleemoplossing en code-optimalisatie.
De Basis van Applicatie Performance: Eindgebruikers ervaring
Het meten van de beschikbaarheid, responstijd en het gedrag van elke zakelijke transactie is essentieel om de hele gebruikers keten te begrijpen. Wanneer een gebruiker een transactie uitvoert op een digitale zakelijke service, moet de eigenaar van de applicatie het volgende weten:
- Reageert de applicatie zoals het hoort?
- Worden alle backend-processen uitgevoerd zoals het hoort?
- Is er enige traagheid is in de transactieverwerking, Zoja, welk deel van de applicatie architectuur veroorzaakt dit?
- Zit er nu een fout/bug zit in de applicatiecode, een probleem in de applicatieserver of in de web-frontend, een traag uitgevoerde query, een hotspot in de database, een traag netwerk, enz.
Monitoring moet dus blijven ontwikkelen van alleen kijken naar hardwarestatistieken naar het analyseren van applicatiecodes en zakelijke transacties. De performance van een applicatie moet worden gemeten met de gebruiker centraal. Dit vormt de basis van Application Performance Monitoring (APM).
Wat is de uitdaging van Applicatie Performance Monitoring?
De meeste moderne applicaties bestaan uit meerdere lagen van componenten die samenwerken om de applicatie te laten werken. Een website kan bijvoorbeeld verschillende frontends van webservers, enkele middleware servers en backend database servers bevatten. Het gebruik van meerdere lagen betekent dat er meer elementen zijn die goed samen moeten functioneren om de applicatie als geheel goed te laten presteren. Wanneer zich een probleem voordoet, maakt de multi-tier architectuur de diagnose moeilijker. Welke van de niveaus veroorzaakt het probleem?
De infrastructuur die wordt gebruikt, kan on-premises of in de cloud zijn. De infrastructuur kan worden beheerd door één team, de server OS kan de verantwoordelijkheid zijn van een ander team en de applicatie kan de verantwoordelijkheid zijn van nog een ander team. Omdat elk team verschillende toolsets gebruikt voor monitoring en beheer, is er geen duidelijk overzicht en correlatie van waaruit IT beheerders kunnen bepalen waarom een applicatie traag is.
Five Aspects of Application Performance Monitoring
Een APM-oplossing die u implementeert, zou idealiter de volgende vijf mogelijkheden moeten hebben:
- Digitale eindgebruikers monitoring: Dit houdt zich bezig met het volgen van de ervaring van applicatiegebruikers en het identificeren van tijden waarop ze traagheid, fouten en downtime ervaren. Er zijn twee populaire benaderingen om dit te doen: Synthetische Simulatie van gebruikers transacties en ze proactief vanaf verschillende locaties te testen; en door passief toezicht te houden op het monitoren van de gebruikerservaring van echte gebruikers terwijl zij in realtime toegang hebben tot de applicaties.
- Transacties in kaart brengen: Dit omvat het in kaart brengen van de code tijdens de looptijd van de applicatie en het analyseren van de transactiestroom door elke laag van de applicatie-architectuur. Dit om te isoleren waar een eventuele bottleneck wordt veroorzaakt. Met behulp van een “tag-and-follow” aanpak kunnen transacties worden getraceerd via de front-end, via de middleware en helemaal tot aan de back-end database.
- Applicatie code-level diagnostiek: Wanneer uit de transactie tracering blijkt dat er traagheid optreedt op de applicatieserver, moet de applicatieontwikkelaar weten of er een probleem is met de applicatiecode. Volgens een enquête van DZone is 43% van de prestatie problemen van applicaties toe te kennen aan een probleem in de code. Het in kaart brengen van de transactie biedt ontwikkelaars de mogelijkheid om in de code in te zoomen.
- Applicatie deep-dive analyse: Wanneer er een probleem is in de applicatie-infrastructuur, bijvoorbeeld in de applicatie server, als er een hoge wachttijd is voor threads, of in het JVM- of .NET wanneer Garbage Collection vaak plaatsvindt of er onvoldoende geheugen is, dan zal het zal de prestaties van de applicatie beïnvloeden. Gedetailleerd inzicht in de applicatie-infrastructuur is een must voor iedere beheerder!
- Zichtbaarheid van Applicatie Performance: Veel applicatieproblemen treden op als gevolg van trage netwerkconnectiviteit, een geheugen probleem in de server, virtualizatie bottlenecks, storage hotspots, etc. Het bewaken van de gezondheid en beschikbaarheid van de ondersteunende infrastructuur is dus van het grootste belang om het succes van de applicatieprestaties te garanderen. Infrastructuur monitoring zou als toevoeging van applicatie monitoring moeten zijn en zou idealiter moeten worden geïntegreerd in een APM-oplossing.
Waarom wint APM aan populariteit?
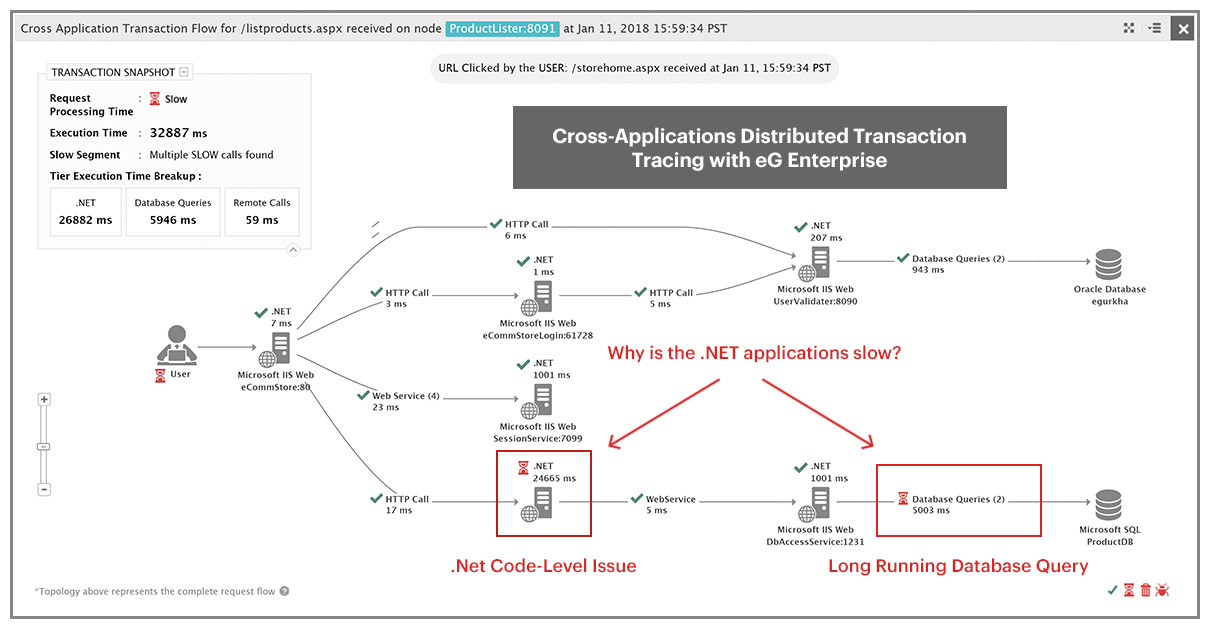
Van alle hierboven gedefinieerde APM-mogelijkheden is transactie profilering de belangrijkste. De reden is dat transactie profilering helpt bij het bepalen van de tijd die in elke applicatie laag wordt doorgebracht. Dit helpt om de oorzaak van traagheid nauwkeurig te vinden. Als het probleem zich in de applicatie bevindt, kan transactie profilering u vertellen waar het zich bevindt; zit het in de toepassingscode, welke methode of regel of code, of is het te wijten aan een SQL query, of is het te wijten aan een externe/derde -partyservice die door de applicatie wordt gebruikt? Deze informatie is van cruciaal belang voor een snelle en snelle probleemdiagnose en oplossing.
Met transactie profilering kan een applicatie eigenaar duidelijk identificeren welke laag/domein verantwoordelijk is voor een probleem. Op deze manier vullen APM-tools de traditionele tools aan.
In een omgeving met meerdere domeinen is de cross-tier zichtbaarheid die transactie profilering biedt van cruciaal belang. Om transactie profilering te laten slagen, moet de overhead laag zijn, dat wil zeggen dat de schaalbaarheid van de applicatie niet mag worden aangetast. Transactie profilering moet zo worden uitgevoerd dat de applicatie code niet opnieuw hoeft te worden geschreven. Op deze manier kunnen zelfs kant-en-klare commerciële toepassingen worden geprofileerd.
Het is gedaan met de “It is Not Me” stelling
In het verleden hebben IT teams eindeloze uren besteed aan ‘brandje blussen’ problemen. Het was moeilijk om het probleem zichtbaar te maken. De database beheerder wil niet dat de applicatie-eigenaar weet hoe zijn/haar database functioneert. Op dezelfde manier wil de applicatie eigenaar geen details van zijn/haar applicatie bekendmaken aan het netwerk team enzovoort.
 Als gevolg hiervan had elk IT domein zijn eigen monitoringtools en wanneer de applicatie traag was, was het erg moeilijk om te bepalen waar het probleem ligt. Transactieprofilering is een uitkomst voor applicatie eigenaren. Zonder speciale machtigingen van de verschillende domeinbeheerders, kunnen zij nu zelf bijhouden waar de tijd wordt besteed. Dit betekent dat agents niet op de databaseservers hoeven te worden ingezet, en zelfs zonder dit kunnen applicatie eigenaren nog steeds inzicht krijgen in hoe goed de database query’s worden verwerkt en kunnen ze bewijzen dat de traagheid van de applicatie te wijten is aan een vertraging van de database bijvoorbeeld. Dit is een ongelooflijk krachtige mogelijkheid en helpt de IT efficiëntie aanzienlijk verbeteren.
Als gevolg hiervan had elk IT domein zijn eigen monitoringtools en wanneer de applicatie traag was, was het erg moeilijk om te bepalen waar het probleem ligt. Transactieprofilering is een uitkomst voor applicatie eigenaren. Zonder speciale machtigingen van de verschillende domeinbeheerders, kunnen zij nu zelf bijhouden waar de tijd wordt besteed. Dit betekent dat agents niet op de databaseservers hoeven te worden ingezet, en zelfs zonder dit kunnen applicatie eigenaren nog steeds inzicht krijgen in hoe goed de database query’s worden verwerkt en kunnen ze bewijzen dat de traagheid van de applicatie te wijten is aan een vertraging van de database bijvoorbeeld. Dit is een ongelooflijk krachtige mogelijkheid en helpt de IT efficiëntie aanzienlijk verbeteren.
Als het gaat om applicatie prestaties, is reproduceerbaarheid een ander aspect om in gedachten te houden. Vaak doen zich problemen voor in productiesystemen en kunnen ze niet worden gereproduceerd in een scenario. IT beheer teams vragen zich af wat het probleem heeft veroorzaakt. En omdat de oorzaak van het probleem niet is opgelost, kan hetzelfde probleem zich opnieuw voordoen.
Transactieprofilering geeft gedetailleerde inzichten van een productie implementatie waarmee IT teams de oorzaak van prestatieproblemen met applicaties kunnen bepalen en deze eenvoudig en nauwkeurig kunnen oplossen.
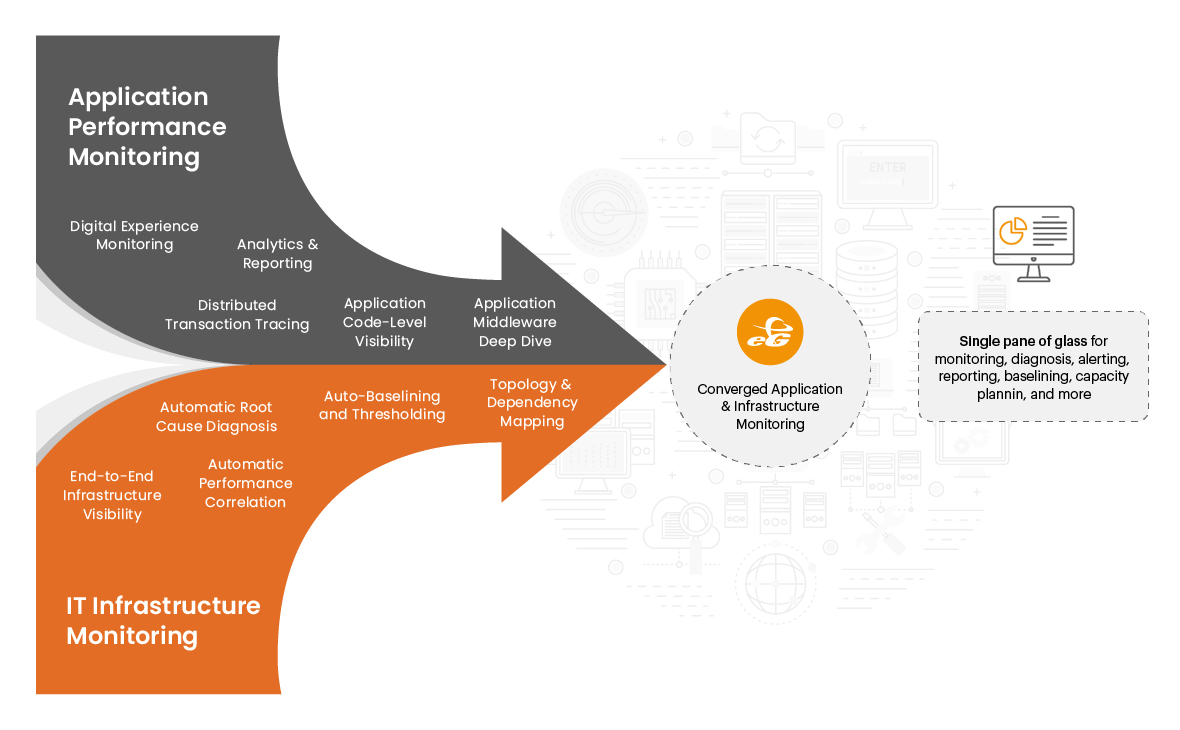
De Rol van Converged Application en Infrastructuur Performance Monitoring
Houd er tegelijkertijd rekening mee dat vertragingen van applicaties ook kunnen worden veroorzaakt door infrastructuur problemen. Het uitvallen van een schijf, overmatige inzet van gevirtualiseerde resources, problemen met het cloud platform, enz. kunnen er allemaal voor zorgen dat een applicatie traag wordt. Alleen Transactieprofilering of een bredere APM mogelijkheid bieden onvoldoende informatie om dergelijke problemen op te lossen. Dit is waar een samengevoegde benadering van applicatie- en infrastructuur monitoring noodzakelijk wordt.
In de afgelopen jaren hebben infrastructuur monitoring tools, zoals Datadog, SolarWinds, Splunk en anderen mogelijkheden voor monitoring van applicatie performance in hun toolsets opgenomen. De traditionele APM tools, zoals Appdynamics en Dynatrace, hebben daarentegen ook mogelijkheden voor monitoring van de infrastructuur toegevoegd aan hun portfolio.
Converged Applicatie en Infrastructuur Monitoring
Veel van deze leveranciers hebben verschillende toolsets geïntegreerd om dit te bewerkstelligen. Bij eG Innovations hebben we een echte converged aanpak voor applicatie en infrastructuur monitoring:
- Dezelfde agent die de infrastructuur bewaakt, bewaakt ook de applicatie-stacks.
- Kleur gecodeerde service topologie weergaven bieden inzicht in infrastructuur prestaties, terwijl middels inzoomen men het inzicht krijgt in de prestaties van applicatie.
- Geautomatiseerde probleem oplossing wordt mogelijk gemaakt door een gepatenteerde rootcause diagnose techniek die rekening houdt met alle vormen van afhankelijkheden: applicatie-naar-applicatie, applicatie-naar-VM, VM-naar-fysieke machine, enz.

eG Enterprise is an Observability solution for Modern IT. Monitor digital workspaces,
web applications, SaaS services, cloud and containers from a single pane of glass.


